ART运行时Semi-Space(SS)和Generational Semi-Space(GSS)GC执行过程分析
Semi-Space(SS)GC和Generational Semi-Space(GSS)GC是ART运行时引进的两个Compacting GC。它们的共同特点是都具有一个From Space和一个To Space。在GC执行期间,在From Space分配的还存活的对象会被依次拷贝到To Space中,这样就可以达到消除内存碎片的目的。本文就将SS GC和GSS GC的执行过程分析进行详细分析。
与SS GC相比,GSS GC还多了一个Promote Space。当一个对象是在上一次GC之前分配的,并且在当前GC中仍然是存活的,那么它就会被拷贝到Promote Space中,而不是To Space中。这相当于是简单地将对象划分为新生代和老生代的,即在上一次GC之前分配的对象属于老生代的,而在上一次GC之后分配的对象属于新生代的。一般来说,老生代对象的存活性要比新生代的久,因此将它们拷贝到Promote Space中去,可以避免每次执行SS GC或者GSS GC时,都需要对它们进行无用的处理。
总结来说,SS GC和GSS GC的执行过程就如图1和图2所示:
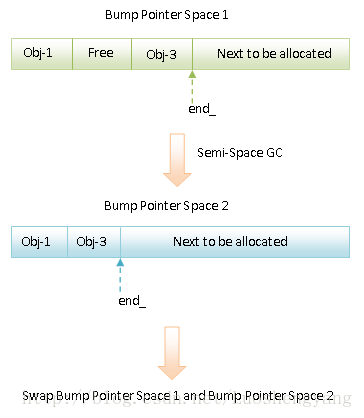
图1 SS GC的执行过程

图2 GSS GC的执行过程
在图1和图2中,Bump Pointer Space 1和Bump Pointer Space 2就是我们前面说的From Space和To Space。接下来我们就结合源码来详细分析它们的执行过程。
从前面ART运行时Compacting GC为新创建对象分配内存的过程分析一文可以知道,在ART运行时内部,都是通过调用Heap类的成员函数CollectGarbageInternal开始执行GC的,因此,我们就从它开始分析SS GC和GSS GC的执行过程。
Heap类的成员函数CollectGarbageInternal的实现如下所示:
collector::GcType Heap::CollectGarbageInternal(collector::GcType gc_type, GcCause gc_cause,
bool clear_soft_references) {
Thread* self = Thread::Current();
Runtime* runtime = Runtime::Current();
......
bool compacting_gc;
{
......
MutexLock mu(self, *gc_complete_lock_);
// Ensure there is only one GC at a time.
WaitForGcToCompleteLocked(gc_cause, self);
compacting_gc = IsMovingGc(collector_type_);
// GC can be disabled if someone has a used GetPrimitiveArrayCritical.
if (compacting_gc && disable_moving_gc_count_ != 0) {
......
return collector::kGcTypeNone;
}
collector_type_running_ = collector_type_;
}
......
collector::GarbageCollector* collector = nullptr;
// TODO: Clean this up.
if (compacting_gc) {
......
switch (collector_type_) {
case kCollectorTypeSS:
// Fall-through.
case kCollectorTypeGSS:
semi_space_collector_->SetFromSpace(bump_pointer_space_);
semi_space_collector_->SetToSpace(temp_space_);
semi_space_collector_->SetSwapSemiSpaces(true);
collector = semi_space_collector_;
break;
case kCollectorTypeCC:
collector = concurrent_copying_collector_;
break;
case kCollectorTypeMC:
mark_compact_collector_->SetSpace(bump_pointer_space_);
collector = mark_compact_collector_;
break;
default:
LOG(FATAL) << "Invalid collector type " << static_cast<size_t>(collector_type_);
}
......
gc_type = collector::kGcTypeFull; // TODO: Not hard code this in.
}
......
collector->Run(gc_cause, clear_soft_references || runtime->IsZygote());
......
RequestHeapTrim();
// Enqueue cleared references.
reference_processor_.EnqueueClearedReferences(self);
// Grow the heap so that we know when to perform the next GC.
GrowForUtilization(collector);
......
FinishGC(self, gc_type);
......
return gc_type;
}这个函数定义在文件art/runtime/gc/heap.cc中。
Heap类的成员函数CollectGarbageInternal首先是调用成员函数WaitForGcToCompleteLocked确保当前没有GC正在执行。如果有的话,那么就等待它执行完成。接下来再调用成员函数IsMovingGc判断当前要执行的GC是否是一个Compacting GC,即判断Heap类的成员变量collector_type_指向的一个垃圾收集器是否是一个Compacting GC类型的垃圾收集器。如果是一个Compacting GC,但是当前又被禁止执行Compacting GC,即Heap类的成员变量disable_moving_gc_count_不等于0,那么当前GC就是禁止执行的。因此在这种情况下,Heap类的成员函数CollectGarbageInternal就什么也不做就直接返回collector::kGcTypeNone给调用者了。
我们只关注Compacting GC的情况,即变量compacting_gc等于true的情况。在ART运行时中,Compacting GC有四种,分别是Semi-Space GC、Generational Semi-Space GC、Mark-Compact GC和Concurrent Copying GC。其中,Semi-Space GC和Generational Semi-Space GC使用的是同一个垃圾收集器,保存在Heap类的成员变量semi_space_collector_中,区别只在于前者不支持分代而后者支持;Mark-Compact GC和Concurrent Copying GC使用的垃圾收集器保存在Heap类的成员变量mark_compact_collector_和concurrent_copying_collector_中。但是,Concurrent Copying GC在Android 5.0中还没有具体实现,因此实际上就只有前面三种Compacting GC。
Heap类的成员变量semi_spacecollector、mark_compact_collector_和concurrent_copying_collector_的初始化发生在Heap类的构造函数中,如下所示:
Heap::Heap(size_t initial_size, size_t growth_limit, size_t min_free, size_t max_free,
double target_utilization, double foreground_heap_growth_multiplier,
size_t capacity, size_t non_moving_space_capacity, const std::string& image_file_name,
const InstructionSet image_instruction_set, CollectorType foreground_collector_type,
CollectorType background_collector_type, size_t parallel_gc_threads,
size_t conc_gc_threads, bool low_memory_mode,
size_t long_pause_log_threshold, size_t long_gc_log_threshold,
bool ignore_max_footprint, bool use_tlab,
bool verify_pre_gc_heap, bool verify_pre_sweeping_heap, bool verify_post_gc_heap,
bool verify_pre_gc_rosalloc, bool verify_pre_sweeping_rosalloc,
bool verify_post_gc_rosalloc, bool use_homogeneous_space_compaction_for_oom,
uint64_t min_interval_homogeneous_space_compaction_by_oom)
......
if (kMovingCollector) {
// TODO: Clean this up.
const bool generational = foreground_collector_type_ == kCollectorTypeGSS;
semi_space_collector_ = new collector::SemiSpace(this, generational,
generational ? "generational" : "");
garbage_collectors_.push_back(semi_space_collector_);
concurrent_copying_collector_ = new collector::ConcurrentCopying(this);
garbage_collectors_.push_back(concurrent_copying_collector_);
mark_compact_collector_ = new collector::MarkCompact(this);
garbage_collectors_.push_back(mark_compact_collector_);
}
......
}这个函数定义在文件art/runtime/gc/heap.cc中。
从这里就可以看出,Heap类的成员变量semi_spacecollector、mark_compact_collector_和concurrent_copying_collector_指向的对象分别是SemiSpace、MarkCompact和ConcurrentCopying。
这里需要注意的是Heap类的成员变量semi_spacecollector,当ART运行时启动时指定的Foreground GC为Generational Semi-Space GC时,它所指向的SemiSpace就是支持分代的;否则的话,就不支持。
回到Heap类的成员函数CollectGarbageInternal中,当当前执行的GC是Semi-Space GC或者Generational Semi-Space GC时,From Space和To Space分别被设置为Heap类的成员变量bump_pointer_space_和temp_space_描述的Space。从前面ART运行时Compacting GC堆创建过程分析一文可以知道,这两个成员变量描述的Space均为Bump Pointer Space。此外,此时使用的SemiSpace被告知,当GC执行完毕,需要交换From Space和To Space,也就是交换Heap类的成员变量bump_pointer_space_和temp_space_描述的两个Bump Pointer Space。另外,当当前执行的GC是Mark-Compact GC时,只需要指定一个Bump Pointer Space,也就是Heap类的成员变量bump_pointer_space_所指向的Bump Pointer Space。由于Concurrent Copying GC还没有具体的实现,因此我们忽略与它相关的逻辑。
确定好当前Compacting GC所使用的垃圾收集器之后,需要将参数gc_type设置为collector::kGcTypeFull。这表示Compacting类型的GC垃圾收集器只能执行类型为collector::kGcTypeFull。这有区别是Mark-Sweep类型的GC,它们能够执行collector::kGcTypeSticky、collector::kGcTypePartial和collector::kGcTypeFull三种类型的GC。
无论当前的GC使用的是什么样的垃圾收集器,都是从调用它们的成员函数Run开始执行的。在ART运行时中,所有的垃圾收集器都是从GarbageCollector类继承下来的,并且也继承了GarbageCollector类的成员函数Run。因此,在ART运行时中,所有的GC都是从GarbageCollector类的成员函数Run开始的。
GC执行完毕,Heap类的成员函数CollectGarbageInternal还会做以下四件主要的事情:
1. 调用Heap类的成员函数RequestHeapTrim请求对堆内存进行裁剪,也就是将没有使用到的内存归还给内核。
2. 调用Heap类的成员变量reference_processor_指向的一个ReferenceProcessor对象的成员函数EnqueueClearedReferences将那些目标对象已经被回收了的引用对象增加到它们创建时指定的列表中,以便使得应用程序知道有哪些被引用对象引用的目标对象被回收了。
3. 调用Heap类的成员函数GrowForUtilization根据预先设置的堆利用率相应地设置堆的大小。
4. 调用Heap类的成员函数FinishGC通知其它等待当前GC执行完成的ART运行时线程,以便它们可以继续往下执行自己的逻辑。
这四件事情的具体执行过程可以参考前面ART运行时垃圾收集(GC)过程分析一文,这里不再复述。这里我们只关注GC的执行过程,也就是GarbageCollector类的成员函数Run的实现,如下所示:
void GarbageCollector::Run(GcCause gc_cause, bool clear_soft_references) {
ATRACE_BEGIN(StringPrintf("%s %s GC", PrettyCause(gc_cause), GetName()).c_str());
Thread* self = Thread::Current();
uint64_t start_time = NanoTime();
Iteration* current_iteration = GetCurrentIteration();
current_iteration->Reset(gc_cause, clear_soft_references);
RunPhases(); // Run all the GC phases.
// Add the current timings to the cumulative timings.
cumulative_timings_.AddLogger(*GetTimings());
// Update cumulative statistics with how many bytes the GC iteration freed.
total_freed_objects_ += current_iteration->GetFreedObjects() +
current_iteration->GetFreedLargeObjects();
total_freed_bytes_ += current_iteration->GetFreedBytes() +
current_iteration->GetFreedLargeObjectBytes();
uint64_t end_time = NanoTime();
current_iteration->SetDurationNs(end_time - start_time);
if (Locks::mutator_lock_->IsExclusiveHeld(self)) {
// The entire GC was paused, clear the fake pauses which might be in the pause times and add
// the whole GC duration.
current_iteration->pause_times_.clear();
RegisterPause(current_iteration->GetDurationNs());
}
total_time_ns_ += current_iteration->GetDurationNs();
for (uint64_t pause_time : current_iteration->GetPauseTimes()) {
pause_histogram_.AddValue(pause_time / 1000);
}
ATRACE_END();
}这个函数定义在文件art/runtime/gc/collector/garbage_collector.cc中。
GarbageCollector类的成员函数Run最主要的工作就是调用由子类实现的成员函数RunPhases来执行具体的GC过程,其它的额外工作就是统计GC执行完成后释放的对象数和内存字节数,以及统计GC执行过程中的停顿时间等。这些统计数据有利于我们分析不同GC的执行性能。
这篇文章我们只关注Semi-Space GC和Generational Semi-Space GC的执行过程中,因此,接下来我们就继续分析SemiSpace类的成员函数RunPhases的实现,如下所示:
void SemiSpace::RunPhases() {
Thread* self = Thread::Current();
InitializePhase();
// Semi-space collector is special since it is sometimes called with the mutators suspended
// during the zygote creation and collector transitions. If we already exclusively hold the
// mutator lock, then we can't lock it again since it will cause a deadlock.
if (Locks::mutator_lock_->IsExclusiveHeld(self)) {
......
MarkingPhase();
ReclaimPhase();
......
} else {
Locks::mutator_lock_->AssertNotHeld(self);
{
ScopedPause pause(this);
......
MarkingPhase();
}
{
ReaderMutexLock mu(self, *Locks::mutator_lock_);
ReclaimPhase();
}
......
}
FinishPhase();
}这个函数定义在文件art/runtime/gc/collector/semi_space.cc中。
从这里就可以看出,Semi-Space GC和Generational Semi-Space GC的执行过程可以分为四个阶段:
1. 初始化阶段;
2. 标记阶段;
3. 回收阶段;
4. 结束阶段。
其中,标记阶段需要在挂起除当前线程之外的其它所有ART运行时线程的前提下执行,回收阶段则需要在获得Locks::mutator_lock_锁的前提下执行。但是由于在执行同构空间压缩和Foreground/Background GC切换时,会使用到Semi-Space GC或者Generational Semi-Space GC,并且这两个操作均是在挂起除当前线程之外的其它所有ART运行时线程的前提下执行的,而这个挂起操作同时也会获取Locks::mutator_lock_锁,因此,SemiSpace类的成员函数RunPhases在执行回收阶段时,就需要作出决定需不需要执行获取Locks::mutator_lock_锁的操作。这个决定是必要的,因为Locks::mutator_lock_不是一个递归锁,也就是不允许同一个线程重复获得,否则的话就会进入死锁状态。关于锁要不要支持递归获取,技术是没有任何问题的,但是需要考虑的是对程序逻辑的影响。一般来说,支持递归锁不是一个好主意,详细说明可以参考这篇文章:http://dev.chromium.org/developers/lock-and-condition-variable。
基于上述原因,SemiSpace类的成员函数RunPhases在执行标记阶段和回收阶段之前,先判断一下当前线程是否已经获得了Locks::mutator_lock_锁。如果已经获得,那么就说明除当前线程之外的其它所有ART运行时线程均已被挂起,因此这里就可以直接执行它们。否则的话,就是要在执行标记阶段之前,挂起除当前线程之外的其它所有ART运行时线程,并且在执行回收阶段之前,先获取Locks::mutator_lock_锁。
其中,挂起除当前线程之外的其它所有ART运行时线程是通过ScopedPause类来实现。ScopedPause类对象在构造的时候,会挂起除当前线程之外的其它所有ART运行时线程,并且在析构时,自动唤醒这些被挂起的ART运行时线程,如下所示:
GarbageCollector::ScopedPause::ScopedPause(GarbageCollector* collector)
: start_time_(NanoTime()), collector_(collector) {
Runtime::Current()->GetThreadList()->SuspendAll();
}
GarbageCollector::ScopedPause::~ScopedPause() {
collector_->RegisterPause(NanoTime() - start_time_);
Runtime::Current()->GetThreadList()->ResumeAll();
}这两个函数定义在文件art/runtime/gc/collector/garbage_collector.cc。
其中,ScopedPause类的构造函数和析构函数还会记录由挂起线程而引发的程序停顿时间。
回到SemiSpace类的成员函数RunPhases,接下来我们就分别分析上述的Semi-Space GC和Generational Semi-Space GC的四个阶段的执行过程。
初始化阶段由SemiSpace类的成员函数InitializePhase来执行,它的实现如下所示:
void SemiSpace::InitializePhase() {
TimingLogger::ScopedTiming t(__FUNCTION__, GetTimings());
mark_stack_ = heap_->GetMarkStack();
DCHECK(mark_stack_ != nullptr);
immune_region_.Reset();
is_large_object_space_immune_ = false;
saved_bytes_ = 0;
bytes_moved_ = 0;
objects_moved_ = 0;
self_ = Thread::Current();
CHECK(from_space_->CanMoveObjects()) << "Attempting to move from " << *from_space_;
// Set the initial bitmap.
to_space_live_bitmap_ = to_space_->GetLiveBitmap();
{
// TODO: I don't think we should need heap bitmap lock to Get the mark bitmap.
ReaderMutexLock mu(Thread::Current(), *Locks::heap_bitmap_lock_);
mark_bitmap_ = heap_->GetMarkBitmap();
}
if (generational_) {
promo_dest_space_ = GetHeap()->GetPrimaryFreeListSpace();
}
fallback_space_ = GetHeap()->GetNonMovingSpace();
}这个函数定义在文件art/runtime/gc/collector/semi_space.cc中。
SemiSpace类的成员函数InitializePhase除了初始化一些成员变量之外,最重要的就是获得ART运行时堆的两个Space:
1. Promote Space。如果当前执行的是Generational Semi-Space GC,那么就需要获取Promote Space,这是通过调用Heap类的成员函数GetPrimaryFreeListSpace获得的。前面提到,Promote Space是用来保存那些老生代对象的。
2. Fallback Space。无论当前执行的是Semi-Space GC还是Generational Semi-Space GC,都需要获取这个Space,这是通过Heap类的成员函数GetNonMovingSpace获得的,也就是ART运行时堆的Non Moving Space。Fallback Space的作用是To Space空间已满时,可以将From Space的对象移动到Fallback Space上去。
Heap类的成员函数GetPrimaryFreeListSpace返回来的实际上是ART运行时堆的Main Space,如下所示:
class Heap {
public:
......
space::MallocSpace* GetPrimaryFreeListSpace() {
if (kUseRosAlloc) {
DCHECK(rosalloc_space_ != nullptr);
// reinterpret_cast is necessary as the space class hierarchy
// isn't known (#included) yet here.
return reinterpret_cast<space::MallocSpace*>(rosalloc_space_);
} else {
DCHECK(dlmalloc_space_ != nullptr);
return reinterpret_cast<space::MallocSpace*>(dlmalloc_space_);
}
}
......
};这个函数定义在文件art/runtime/gc/heap.h中。
从前面ART运行时Compacting GC堆创建过程分析一文可以知道,Heap类的成员变量rosalloc_space_和dlmalloc_space_描述的就是ART运行时堆的Main Space。取决于常量kUseRosAlloc的值。它由Heap类的成员变量rosalloc_space_或者dlmalloc_space_指向。
从前面ART运行时Compacting GC堆创建过程分析一文也可以知道,对于Generational Semi-Space GC来说,它的Main Space其实也是Non Moving Space,这意味着Generational Semi-Space GC使用的Promote Space和Fallback Space均为ART运行时堆的Non Moving Space。
标记阶段由SemiSpace类的成员函数MarkingPhase来执行,它的实现如下所示:
void SemiSpace::MarkingPhase() {
......
// Revoke the thread local buffers since the GC may allocate into a RosAllocSpace and this helps
// to prevent fragmentation.
RevokeAllThreadLocalBuffers();
if (generational_) {
if (GetCurrentIteration()->GetGcCause() == kGcCauseExplicit ||
GetCurrentIteration()->GetGcCause() == kGcCauseForNativeAlloc ||
GetCurrentIteration()->GetClearSoftReferences()) {
// If an explicit, native allocation-triggered, or last attempt
// collection, collect the whole heap.
collect_from_space_only_ = false;
}
......
}
if (!collect_from_space_only_) {
// If non-generational, always clear soft references.
// If generational, clear soft references if a whole heap collection.
GetCurrentIteration()->SetClearSoftReferences(true);
}
Locks::mutator_lock_->AssertExclusiveHeld(self_);
if (generational_) {
// If last_gc_to_space_end_ is out of the bounds of the from-space
// (the to-space from last GC), then point it to the beginning of
// the from-space. For example, the very first GC or the
// pre-zygote compaction.
if (!from_space_->HasAddress(reinterpret_cast<mirror::Object*>(last_gc_to_space_end_))) {
last_gc_to_space_end_ = from_space_->Begin();
}
// Reset this before the marking starts below.
bytes_promoted_ = 0;
}
// Assume the cleared space is already empty.
BindBitmaps();
// Process dirty cards and add dirty cards to mod-union tables.
heap_->ProcessCards(GetTimings(), kUseRememberedSet && generational_);
......
heap_->GetCardTable()->ClearCardTable();
// Need to do this before the checkpoint since we don't want any threads to add references to
// the live stack during the recursive mark.
if (kUseThreadLocalAllocationStack) {
......
heap_->RevokeAllThreadLocalAllocationStacks(self_);
}
heap_->SwapStacks(self_);
{
WriterMutexLock mu(self_, *Locks::heap_bitmap_lock_);
MarkRoots();
// Recursively mark remaining objects.
MarkReachableObjects();
}
ProcessReferences(self_);
{
ReaderMutexLock mu(self_, *Locks::heap_bitmap_lock_);
SweepSystemWeaks();
}
// Revoke buffers before measuring how many objects were moved since the TLABs need to be revoked
// before they are properly counted.
RevokeAllThreadLocalBuffers();
// Record freed memory.
const int64_t from_bytes = from_space_->GetBytesAllocated();
const int64_t to_bytes = bytes_moved_;
const uint64_t from_objects = from_space_->GetObjectsAllocated();
const uint64_t to_objects = objects_moved_;
......
// Note: Freed bytes can be negative if we copy form a compacted space to a free-list backed
// space.
RecordFree(ObjectBytePair(from_objects - to_objects, from_bytes - to_bytes));
// Clear and protect the from space.
from_space_->Clear();
......
from_space_->GetMemMap()->Protect(kProtectFromSpace ? PROT_NONE : PROT_READ);
......
if (swap_semi_spaces_) {
heap_->SwapSemiSpaces();
}
}这个函数定义在文件art/runtime/gc/collector/semi_space.cc中。
SemiSpace类的成员函数MarkingPhase的执行过程如下所示:
1. 调用SemiSpace类的成员函数RevokeAllThreadLocalBuffers回收各个ART运行时线程的局部分配缓冲区。从前面ART运行时Compacting GC为新创建对象分配内存的过程分析这篇文章可以知道,ART运行时线程的局部分配缓冲区是来自Bump Pointer Space或者Ros Alloc Space的。由于现在要对Bump Pointer Space进行GC处理了,因此就需要把它作为ART运行时线程局部分配缓冲区的那部内存回收回来。避免GC处理完毕后,ART运行时线程的局部分配缓冲区引用到不正确内存。
2. Generational Semi-Space GC在执行时,默认只对From Space进行处理,即当SemiSpace类的成员变量generational_与collect_from_space_only_的值是相同的。但是如果当前的Generational Semi-Space GC是在以下三种情况下执行:
1) 应用程序显示请求执行;
2) 由于要分配Native内存而触发执行;
3) 请求回收那些只被软引用对象引用的对象。
上述三种情况都是表达当前内存较紧张,因此就不能只是回收From Space的内存,还应该考虑回收其它Space的内存,例如Non Moving Space的内存。
- Semi-Space GC在执行时,默认不仅对From Space的内存进行处理,也对其它的Space的内存进行处理,例如Non Moving Space的内存,而且也会对那些只被软引用对象引用的对象进行处理,因此这种情况需要将该次GC标记为清理软引用对象。
4. 对于Generational Semi-Space GC,需要有一个标准区分新生代和老生代对象,以便后面可以确定哪些对象要移动到Promote Space,哪些对象要移动到To Space。每次Generational Semi-Space GC执行完毕,To Space当前使用的内存的最大值都会记录在SemiSpace类的成员变量last_gc_to_space_end_中。这样,下次再执行Generational Semi-Space GC时,对于From Space(即上次GC时的To Space)的对象来说,地址小于last_gc_to_space_end_都是属于老生代对象,而大于等于last_gc_to_space_end_都大于新生代对象。这也意味着在执行Generational Semi-Space GC时,我们要保证last_gc_to_space_end_的值要位于From Space的地址空间范围内,否则的话,上述的判断逻辑就会存在问题。
但是在第一次Generational Semi-Space GC执行之前,SemiSpace类的成员变量last_gc_to_space_end_是初始化为nullptr的,因此这种情况就需要将其重新初始化为From Space的起始值。还有另外一种不是第一次执行Generational Semi-Space GC的情况,也需要重新初始化SemiSpace类的成员变量last_gc_to_space_end_的值为From Space的起始值。这种情况就发生在Zygote进程fork第一个子进程之前执行的那次Compact Zygote操作中。我们假设Zygote进程fork第一次子进程前,已经执行过一次Generational Semi-Space GC,然后当前的GC又被切换为Mark-Sweep GC。现在执行Compact Zygote操作,从前面ART运行时Compacting GC为新创建对象分配内存的过程分析这篇文章可以知道,这时候的From Space并不是上次Generational Semi-Space GC的To Space,而是ART运行时堆的Main Space。这样上次记录的last_gc_to_space_end_的值肯定不是在Main Space的地址空间范围之内。因此。这种情况也需要将SemiSpace类的成员变量last_gc_to_space_end_的值为From Space的起始值。
5. 做好前面的四个准备工作后,就可以调用Heap类的成员函数BindBitmaps确定当前GC要处理的Space了。这一方面是与Space的回收策略有关,例如,Image Space的回收策略为kGcRetentionPolicyNeverCollect,那么它的内存就永远不会被回收。另一方面也与SemiSpace类的成员变量collect_from_space_only_的值有关。
6. 调用Heap类的成员函数ProcessCards处理ART运行时的Dirty Card。从前面ART运行时垃圾收集(GC)过程分析一文可以知道,这实际上就是将Dirty Card都收集起来,以便后面可以对它们进行处理。
7. 从前面的分析可以知道,Semi-Space GC和Generational Semi-Space GC的标记阶段是在挂起除当前线程之外的所有其它ART运行时线程的前提下执行的。因此,可以保证在刚才处理Dirty Card的过程中,Dirty Card不会被并行修改,因此这时候就可以安全地对其执行清理工作,这是通过调用CardTable类的成员函数ClearCardTable实现的。
8. 每个ART运行时线程除了有一个局部分配缓冲区之外,还有一个局部Allocation Stack。局部Allocation Stack与局部分配缓冲区是类似的,它们都是为了解决在多线程情况下需要加锁才能访问公共的Allocation Stack和分配缓冲区的问题。因此,这里对局部Allocation Stack的处理与对局部分配缓冲区的处理类似,都是需要对它们进行回收。这是通过调用Heap类的成员函数RevokeAllThreadLocalAllocationStacks来实现的。
9. 调用Heap类的成员函数SwapStacks交换ART运行时的Allocation Stack和Live Stack。这是每次GC都必须执行的操作,为了以后能够正确地执行Sticky GC。
10. 现在终于可以进入我们熟悉的对象递归标记过程了。首先是调用SemiSpace类的成员函数MarkRoots找到根集对象,然后再调用SemiSpace类的成员函数MarkReachableObjects递归标记从根集对象可达的对象。对于不是要对所有的Space都进行处理的GC来说,根集对象只包含那些位于当前需要处理的Space。但是在标记可达对象时,就不仅需要考虑从根集对象可达的对象,还需要考虑从Dirty Card可达的对象。举个例子说,堆有A、B和C三个Space,现在要对B和C进行处理。从B和C的根集对象开始,可以找到B和C的所有可达对象。但是这时候并不意味着B和C的不可达对象就是可以回收的。因为A的对象自上次GC以来,可能修改了某些成员变量,使得它们引用了B和C的对象。也就是说,这部分被A的对象引用的B和C的对象不能回收。由于我们可以通过Dirty Card来获得A的对象的修改信息,因此结合Dirty Card,我们就可以正确地将B和C的所有可达对象都标记出来。这部分逻辑也是SemiSpace类的成员函数MarkReachableObjects负责完成的。
11. 调用SemiSpace类的成员函数ProcessReferences处理引用对象。这个处理过程可以参考前面ART运行时垃圾收集(GC)过程分析一文的分析。
- 调用SemiSpace类的成员函数SweepSystemWeaks处理那些没有被标记的常量字符串、Monitor对象和在JNI创建的全局弱引用对象等。这个处理过程可以参考前面ART运行时垃圾收集(GC)过程分析一文的分析。
13. 调用从父类GarbageCollector继承下来的成员函数RecordFree统计当前GC释放的对象数和内存字节数。由Semi-Space GC和Generational Semi-Space GC在标记对象的过程就实现了对象移动。这意味着没有被移动的对象就是需要回收其占用的内存的对象,因此当标记阶段结束后,就可以知道当前GC释放的对象数和内存字节数了。在调用GarbageCollector类的成员函数RecordFree统计当前GC释放的对象数和内存字节数之前,这里又重复调用了前面提到的SemiSpace类的成员函数RevokeAllThreadLocalBuffers来回收各个ART运行时线程的局部分配缓冲区。这似乎是不必要的,因此这时候除了当前线程之外,其他的ART运行时线程都是被挂起的,也就是说它们不会有修改其局部分配缓冲区的机会。
14. 这时候From Space就派不上用场了,因为它里面的对象要么是被移动到了To Space或者Promote Space的,要么是要回收的。这时候就可以将From Space使用的内存地址清零,并且将它们的标志设置为PROT_NONE或者PROT_READ。也就是说,将From Space使用的内存地址设置为不可写入。这样如果对From Space发生了写操作,就能够检测出来。这是一种错误的行为,因为这个From Space即将被设置为下一次GC的To Space,而To Space只有等到下一次GC时才允许写入操作。
15. 如果Semi-Space GC或者Generational Semi-Space GC在执行之前,设置了交换From Space和To Space的标志,也就是SemiSpace类的成员变量swap_semi_spaces_设置为true,那么就调用Heap类的成员函数SwapSemiSpaces交换From Space和To Space。
在以十五个操作中第1、5、8和10这四个操作,对应的函数分别为SemiSpace类的成员函数RevokeAllThreadLocalBuffers、SemiSpace类的成员函数BindBitmaps、Heap类的成员函数RevokeAllThreadLocalAllocationStacks、SemiSpace类的成员函数MarkRoots和SemiSpace类的成员函数MarkReachableObjects。接下来我们就分别对它们进行分析,以便可以更好理解Semi-Space GC或者Generational Semi-Space GC的标记阶段。
SemiSpace类的成员函数RevokeAllThreadLocalBuffers的实现如下所示:
void SemiSpace::RevokeAllThreadLocalBuffers() {
TimingLogger::ScopedTiming t(__FUNCTION__, GetTimings());
GetHeap()->RevokeAllThreadLocalBuffers();
}这个函数定义在文件art/runtime/gc/collector/semi_space.cc中。
SemiSpace类的成员函数RevokeAllThreadLocalBuffers调用Heap类的成员函数RevokeAllThreadLocalBuffers来回收所有ART运行时线程的局分配缓冲区,后者的实现如下所示:
void Heap::RevokeAllThreadLocalBuffers() {
if (rosalloc_space_ != nullptr) {
rosalloc_space_->RevokeAllThreadLocalBuffers();
}
if (bump_pointer_space_ != nullptr) {
bump_pointer_space_->RevokeAllThreadLocalBuffers();
}
}这个函数定义在文件art/runtime/gc/heap.cc中。
从前面ART运行时Compacting GC为新创建对象分配内存的过程分析一文可以知道,ART运行时线程的局部分配缓冲区来自于Ros Alloc Space或者Bump Pointer Space,这取决于当前使用的GC是Mark-Sweep GC还是Compacting GC。
从这里就可以看到,来自于Ros Alloc Space和Bump Pointer Space的ART运行时线程局部分缓冲区分别是通过调用RosAllocSpace类和BumpPointerSpace类的成员函数RevokeAllThreadLocalBuffers来回收的。
RosAllocSpace类的成员函数RevokeAllThreadLocalBuffers的实现如下所示:
void RosAllocSpace::RevokeAllThreadLocalBuffers() {
rosalloc_->RevokeAllThreadLocalRuns();
}这个函数定义在文件art/runtime/gc/space/rosalloc_space.cc中。
RosAllocSpace类的成员变量rosalloc_指向的是一个RosAlloc对象,因此RosAllocSpace类的成员函数RevokeAllThreadLocalBuffers通过调用RosAlloc类的成员函数RevokeAllThreadLocalRuns来回收ART运行时线程局部分缓冲区,后者的实现如下所示:
void RosAlloc::RevokeAllThreadLocalRuns() {
// This is called when a mutator thread won't allocate such as at
// the Zygote creation time or during the GC pause.
MutexLock mu(Thread::Current(), *Locks::runtime_shutdown_lock_);
MutexLock mu2(Thread::Current(), *Locks::thread_list_lock_);
std::list<Thread*> thread_list = Runtime::Current()->GetThreadList()->GetList();
for (Thread* thread : thread_list) {
RevokeThreadLocalRuns(thread);
}
RevokeThreadUnsafeCurrentRuns();
}这个函数定义在文件art/runtime/gc/allocator/rosalloc.cc中。
RosAlloc类的成员函数RevokeAllThreadLocalRuns首先是获得ART运行时线程列表,然后再调用另外一个成员函数RevokeThreadLocalRuns对每一个ART运行时线程的局分配缓冲区进行回收。
从前面ART运行时Compacting GC为新创建对象分配内存的过程分析一文可以知道,所有index值小于kNumThreadLocalSizeBrackets的Run都是线程局部的,但是它们不一定是保存在各个线程的一块局部储存中,也有可能是保存在RosAlloc类的成员变量current_runs_描述的一个Run数组中。这取决于在Ros Alloc Space中分配内存时是否是线程安全的。这两种类型的Run分别通过RosAlloc类的成员函数RevokeThreadLocalRuns和RevokeThreadUnsafeCurrentRuns来回收。
RosAlloc类的成员函数RevokeThreadLocalRuns的实现如下所示:
void RosAlloc::RevokeThreadLocalRuns(Thread* thread) {
Thread* self = Thread::Current();
// Avoid race conditions on the bulk free bit maps with BulkFree() (GC).
ReaderMutexLock wmu(self, bulk_free_lock_);
for (size_t idx = 0; idx < kNumThreadLocalSizeBrackets; idx++) {
MutexLock mu(self, *size_bracket_locks_[idx]);
Run* thread_local_run = reinterpret_cast<Run*>(thread->GetRosAllocRun(idx));
......
if (thread_local_run != dedicated_full_run_) {
thread->SetRosAllocRun(idx, dedicated_full_run_);
......
// Note the thread local run may not be full here.
bool dont_care;
thread_local_run->MergeThreadLocalFreeBitMapToAllocBitMap(&dont_care);
thread_local_run->SetIsThreadLocal(false);
thread_local_run->MergeBulkFreeBitMapIntoAllocBitMap();
......
RevokeRun(self, idx, thread_local_run);
}
}
}这个函数定义在文件art/runtime/gc/allocator/rosalloc.cc中。
从这里就可以看到,所有index值小于kNumThreadLocalSizeBrackets的Run都会通过调用Thread类的成员函数GetRosAllocRun从参数thread描述的线程取出来,并且使用RosAlloc类的成员变量dedicated_full_run_描述的一个占坑用的Run替代它。我们在前面ART运行时Compacting GC为新创建对象分配内存的过程分析一文中提到,RosAlloc类的成员变量dedicated_full_run_是不能够分配Slot的,也就是不可能从中分配得到内存的。因此,上述的替换操作实际上就相当于是完成了回收参数thread描述的线程的局部分配缓冲区的操作。 从Thread类的成员函数GetRosAllocRun取回来的Run在真正被回收之前,还需要进行三个处理。
第一个处理是将其Thread Local Free Bit Map的数据合并到Alloc Bit Map中去。当我们从RosAlloc中释放一个对象时,如果这个对象所属于的Run是一个线程局部Run,那么只会将该Run的Thread Local Free Bit Map的对应位设置为1,这样可以避免去操作Alloc Bit Map,因为操作后者是需要加锁的。现在既然这个Run要被回收了,那么就是时候将它的Thread Local Free Bit Map的信息转移到Alloc Bit Map去了。这是通过调用Run类的成员函数MergeThreadLocalFreeBitMapToAllocBitMap实现的。
第二个处理是调用Run类的成员函数SetIsThreadLocal将即将要被回收的Run设置为是非线程局部的。
第三个处理是将其Bulk Free Bit Map的数据合并到Alloc Bit Map中去。当我们从RosAlloc中释放一个对象时,如果这个对象所属于的Run是一个非线程局部Run,那么只会将该Run的Bulk Free Bit Map的对应位设置为1,这样同样是为了避免加锁操作Alloc Bit Map。理论上说,我们现在处理的Run是一个线程局部Run,因此它的Bulk Free Bit Map不会被操作。不过这里似乎是为了安全起见,也会调用Run类的成员函数MergeBulkFreeBitMapIntoAllocBitMap尝试将Bulk Free Bit Map的信息转移到Alloc Bit Map去。
完成了前面的三个处理之后,最后就可以调用RosAlloc类的成员函数RevokeRun执真正的回收工作了,如下所示:
void RosAlloc::RevokeRun(Thread* self, size_t idx, Run* run) {
......
if (run->IsFull()) {
if (kIsDebugBuild) {
full_runs_[idx].insert(run);
......
}
} else if (run->IsAllFree()) {
run->ZeroHeader();
MutexLock mu(self, lock_);
FreePages(self, run, true);
} else {
non_full_runs_[idx].insert(run);
......
}
}这个函数定义在文件art/runtime/gc/allocator/rosalloc.cc中。
如果被回收的Run的所有Slot都已经分配出去,那么在Debug版本中,这个Run会被保存在RosAlloc类的成员变量full_runs_描述的一个数组中。另一方面,如果是在非Debug版本中,就什么也不用做。注意,在后一种情况下,尽管我们没有将要被回收的Run保存在任何一个地方,但是这不会导致被回收的Run丢失,因为当我们释放一个对象,会根据这个对象的地址找到它所在的页,然后再根据页标志重新找到它所在的Run。这一点可以参考RosAlloc类的成员函数BulkFree的实现。
如果被回收的Run的所有Slot都是空闲的,那么就可以调用RosAlloc类的成员函数FreePages将它所占据的内存页封装成一个FreePageRun保存RosAlloc类的成员变量free_page_runs_描述的一个set中去,以便后面可以对它们进行重复利用。
如果被回收的Run只是有部分Slot是已经分配的,那么就将它保存在RosAlloc类的成员变量non_full_runs_描述的一个数组中,以及后面分配一个新的Run时,可以直接从该数组获得。
回到RosAlloc类的成员函数RevokeAllThreadLocalRuns中,处理完成位于ART运行时线程的局部储存的Run之后,接下来再调用成员函数RevokeThreadUnsafeCurrentRuns处理位于成员变量current_runs_的index值小于kNumThreadLocalSizeBrackets的Run,如下所示:
void RosAlloc::RevokeThreadUnsafeCurrentRuns() {
// Revoke the current runs which share the same idx as thread local runs.
Thread* self = Thread::Current();
for (size_t idx = 0; idx < kNumThreadLocalSizeBrackets; ++idx) {
MutexLock mu(self, *size_bracket_locks_[idx]);
if (current_runs_[idx] != dedicated_full_run_) {
RevokeRun(self, idx, current_runs_[idx]);
current_runs_[idx] = dedicated_full_run_;
}
}
}这个函数定义在文件art/runtime/gc/allocator/rosalloc.cc中。
对位于RosAlloc类的成员变量current_runs_的index值小于kNumThreadLocalSizeBrackets的Run的回收同样是通过调用成员函数RevokeRun来实现的,不过由于这些Run是非线程局部的,因此在调用成员函数RevokeRun进行回收之前,不需要做一些额外的处理。
这样,对Ros Alloc Space的线程局部分配缓冲区的回收就完成了,回到Heap类的成员函数RevokeAllThreadLocalBuffers中,接下来我们继续分析BumpPointerSpace类的成员函数RevokeAllThreadLocalBuffers的实现,以便可以了解对Bump Pointer Space的线程局部分配缓冲区的回收过程,如下所示:
void BumpPointerSpace::RevokeAllThreadLocalBuffers() {
Thread* self = Thread::Current();
MutexLock mu(self, *Locks::runtime_shutdown_lock_);
MutexLock mu2(self, *Locks::thread_list_lock_);
// TODO: Not do a copy of the thread list?
std::list<Thread*> thread_list = Runtime::Current()->GetThreadList()->GetList();
for (Thread* thread : thread_list) {
RevokeThreadLocalBuffers(thread);
}
}这个函数定义在文件art/runtime/gc/space/bump_pointer_space.cc中。
BumpPointerSpace类的成员函数RevokeAllThreadLocalBuffers首先是获得ART运行时线程列表,然后再调用另外一个成员函数RevokeThreadLocalBuffers对每一个ART运行时线程的局分配缓冲区进行回收,如下所示:
void BumpPointerSpace::RevokeThreadLocalBuffers(Thread* thread) {
MutexLock mu(Thread::Current(), block_lock_);
RevokeThreadLocalBuffersLocked(thread);
}这个函数定义在文件art/runtime/gc/space/bump_pointer_space.cc中。
BumpPointerSpace类的成员函数RevokeThreadLocalBuffers又是通过调用另外一个成员函数RevokeThreadLocalBuffersLocked来回收参数thread描述的ART运行时线程的局部分配缓冲区的,后者的实现如下所示:
void BumpPointerSpace::RevokeThreadLocalBuffersLocked(Thread* thread) {
objects_allocated_.FetchAndAddSequentiallyConsistent(thread->GetThreadLocalObjectsAllocated());
bytes_allocated_.FetchAndAddSequentiallyConsistent(thread->GetThreadLocalBytesAllocated());
thread->SetTlab(nullptr, nullptr);
}这个函数定义在文件art/runtime/gc/space/bump_pointer_space.cc中。
对Bump Pointer Space来说,线程局部分配缓冲区的回收是相当简单的,首先是将已经从线程局部分配缓冲区分配的对象数和内存字节数增加到整个Bump Pointer Space的已经分配对象数和内存字节数,接着再将线程的线程局部分配缓冲区信息置为空即可,这是通过调用Thread类的成员函数SetTlab来实现的。
这样,我们就分析完成了ART运行时线程的局部分配缓冲区的回收过程,回到SemiSpace类的成员函数MarkingPhase中,我们继续分析ART运行时线程的局部Allocation Stack的回收过程,即Heap类的成员函数RevokeAllThreadLocalAllocationStacks的实现。
不过在分析Heap类的成员函数RevokeAllThreadLocalAllocationStacks的实现之前,我们先要分要Heap类的成员函数PushOnAllocationStack的实现,以便可以了解ART运行时线程的局部Allocation Stack是如何使用的。
从前面ART运行时Compacting GC为新创建对象分配内存的过程分析一文可以知道,当我们从ART运行时堆分配了一个对象之后,如果当前指定的分配器既不是kAllocatorTypeBumpPointer,也不是kAllocatorTypeTLAB,也就是当前使用的GC不是Compacting GC,那么就调用Heap类的成员函数PushOnAllocationStack将前面已经分配得到的对象压入到Allocation Stack中,以便以后可以执行Sticky GC。
Heap类的成员函数PushOnAllocationStack的实现如下所示:
inline void Heap::PushOnAllocationStack(Thread* self, mirror::Object** obj) {
if (kUseThreadLocalAllocationStack) {
if (UNLIKELY(!self->PushOnThreadLocalAllocationStack(*obj))) {
PushOnThreadLocalAllocationStackWithInternalGC(self, obj);
}
} else if (UNLIKELY(!allocation_stack_->AtomicPushBack(*obj))) {
PushOnAllocationStackWithInternalGC(self, obj);
}
}这个函数定义在文件art/runtime/gc/heap-inl.h中。
取决于常量kUseThreadLocalAllocationStack的值,Heap类的成员函数PushOnAllocationStack要么把新分配的对象压入到当前线程的局部Allocation Stack中,要么压入到全局的Allocation Stack中。
当常量kUseThreadLocalAllocationStack的值等于false时,新分配的对象压入到全局Allocation Stack中,即Heap类的成员变量allocation_stack_指向的一个ObjectStack中。如果压入失败,就说明全局Allocation Stack已经满了。因此就需要调用Heap类的成员函数PushOnAllocationStackWithInternalGC执行一次Sticky GC,以便可以将全局Allocation Stack清空再压入新分配的对象。
Heap类的成员函数PushOnAllocationStackWithInternalGC的实现如下所示:
void Heap::PushOnAllocationStackWithInternalGC(Thread* self, mirror::Object** obj) {
// Slow path, the allocation stack push back must have already failed.
DCHECK(!allocation_stack_->AtomicPushBack(*obj));
do {
// TODO: Add handle VerifyObject.
StackHandleScope<1> hs(self);
HandleWrapper<mirror::Object> wrapper(hs.NewHandleWrapper(obj));
// Push our object into the reserve region of the allocaiton stack. This is only required due
// to heap verification requiring that roots are live (either in the live bitmap or in the
// allocation stack).
CHECK(allocation_stack_->AtomicPushBackIgnoreGrowthLimit(*obj));
CollectGarbageInternal(collector::kGcTypeSticky, kGcCauseForAlloc, false);
} while (!allocation_stack_->AtomicPushBack(*obj));
}这个函数定义在文件art/runtime/gc/heap.cc中。
从这里就可以看到,Heap类的成员函数PushOnAllocationStackWithInternalGC先通过调用成员函数CollectGarbageInternal执行一次Sticky GC,然后再尝试将新分配的对象压入到全局Allocation Stack中。此过程一直重复,直到能够成功地将新分配的对象压入到全局Allocation Stack为止。注意,由于在GC的根集标记的堆验证过程中,要求根集对象要么位于Live Bitmap中,要么位于全局Allocation Stack中,因此在执行Sticky GC之前,需要强制地将新分配的对象压入(这时候它是一个根集对象)到全局Allocation Stack中,这是通过调用Heap类的成员变量allocation_stack_指向的一个AtomicStack对象的成员函数AtomicPushBackIgnoreGrowthLimit来实现的。
回到Heap类的成员函数PushOnAllocationStack中,当常量kUseThreadLocalAllocationStack的值等于true时,新分配的对象压入到当前线程的部局Allocation Stack中,这是通过调用参数self指向的一个Thread对象的成员函数PushOnThreadLocalAllocationStack实现的,它的实现如下所示:
inline bool Thread::PushOnThreadLocalAllocationStack(mirror::Object* obj) {
......
if (tlsPtr_.thread_local_alloc_stack_top < tlsPtr_.thread_local_alloc_stack_end) {
......
*tlsPtr_.thread_local_alloc_stack_top = obj;
++tlsPtr_.thread_local_alloc_stack_top;
return true;
}
return false;
}这个函数定义在文件art/runtime/thread-inl.h中。
当前线程的局部Allocation Stack由Thread类的成员变量tlsPtr指向的一块类型为tls_ptr_sized_values的局部储存结构体的成员变量thread_local_alloc_stack_top和thread_local_alloc_stack_end来描述。其中,thread_local_alloc_stack_top描述的是栈顶,而thread_local_alloc_stack_end描述的是栈顶的最大值。
因此,将一个新分配对象压入当前线程的局部Allocation Stack,实际上就是将它的地址保存在当前线程的局部Allocation Stack的栈顶上,然后再将栈顶增加一个单位。
回到Heap类的成员函数PushOnAllocationStack中,如果新分配的对象不能成功压入到当前线程的部局Allocation Stack中,也说明需要执行一次Sticky GC来清理各线程的局部Allocation Stack,以便可以压入新分配的对象。这是通过调用Heap类的成员函数PushOnThreadLocalAllocationStackWithInternalGC来实现的,如下所示:
void Heap::PushOnThreadLocalAllocationStackWithInternalGC(Thread* self, mirror::Object** obj) {
// Slow path, the allocation stack push back must have already failed.
DCHECK(!self->PushOnThreadLocalAllocationStack(*obj));
mirror::Object** start_address;
mirror::Object** end_address;
while (!allocation_stack_->AtomicBumpBack(kThreadLocalAllocationStackSize, &start_address,
&end_address)) {
// TODO: Add handle VerifyObject.
StackHandleScope<1> hs(self);
HandleWrapper<mirror::Object> wrapper(hs.NewHandleWrapper(obj));
// Push our object into the reserve region of the allocaiton stack. This is only required due
// to heap verification requiring that roots are live (either in the live bitmap or in the
// allocation stack).
CHECK(allocation_stack_->AtomicPushBackIgnoreGrowthLimit(*obj));
// Push into the reserve allocation stack.
CollectGarbageInternal(collector::kGcTypeSticky, kGcCauseForAlloc, false);
}
self->SetThreadLocalAllocationStack(start_address, end_address);
// Retry on the new thread-local allocation stack.
CHECK(self->PushOnThreadLocalAllocationStack(*obj)); // Must succeed.
}这个函数定义在文件art/runtime/gc/heap.cc中。
线程局部Allocation Stack使用的内存块实际上来自于全局Allocation Stack。现在由于当前线程的局部Allocation Stack满了,那么理论上就需要从全局Allocation Stack中获取更多的内存来增加当前线程的局部Allocation Stack,以便可以成功地压入新分配的对象。
不过,Heap类的成员函数PushOnThreadLocalAllocationStackWithInternalGC并不是通过增加当前线程原来的局部Allocation Stack的大小来满足压入新分配的对象的需求的,而是尝试从全局Allocation Stack中给当前线程分配另外一块大小为kThreadLocalAllocationStackSize的新内存作为局部Allocation Stack,然后再压入新分配的对象。
从全局Allocation Stack中分配一块新内存是通过调用Heap类的成员变量allocation_stack_指向的一个ObjectStack对象的成员函数AtomicBumpBack来实现的。ObjectStack类定义为AtomicStack<mirror::Object*>,因此从全局Allocation Stack中分配一块新内存实际上是通过调用AtomicStack类的成员函数AtomicBumpBack来实现的,如下所示:
template <typename T>
class AtomicStack {
public:
......
// Atomically bump the back index by the given number of
// slots. Returns false if we overflowed the stack.
bool AtomicBumpBack(size_t num_slots, T** start_address, T** end_address) {
......
int32_t index;
int32_t new_index;
do {
index = back_index_.LoadRelaxed();
new_index = index + num_slots;
if (UNLIKELY(static_cast<size_t>(new_index) >= growth_limit_)) {
// Stack overflow.
return false;
}
} while (!back_index_.CompareExchangeWeakRelaxed(index, new_index));
*start_address = &begin_[index];
*end_address = &begin_[new_index];
......
return true;
}
......
};这个函数定义在文件art/runtime/gc/accounting/atomic_stack.h中。
AtomicStack类的成员变量back_index_描述的是栈顶位置,通过增加它的值即可保留一块内存区域出来作为线程的局部Allocation Stack使用。
回到Heap类的成员函数PushOnThreadLocalAllocationStackWithInternalGC中,如果不能成功从全局Allocation Stack中分配一块新的内存作为当前线程的局部Allocation Stack,那么就只好调用Heap类的成员函数CollectGarbageInternal执行一次Sticky GC来清理全局Allocation Stack,再重新尝试从全局Allocation Stack中分配一块新的内存了。在执行Sticky GC之前,同样是先会把新分配的对象强制压入到全局Allocation Stack中。
给当前线程设置一个新的局部Allocation Stack是通过调用Thread类的成员函数SetThreadLocalAllocationStack来实现的,如下所示:
inline void Thread::SetThreadLocalAllocationStack(mirror::Object** start, mirror::Object** end) {
......
tlsPtr_.thread_local_alloc_stack_end = end;
tlsPtr_.thread_local_alloc_stack_top = start;
}这个函数定义在文件art/runtime/thread-inl.h中。
有了这些基础知识之后,回到SemiSpace类的成员函数MarkingPhase中,继续分析它调用的Heap类的成员函数RevokeAllThreadLocalAllocationStacks的实现了,如下所示:
void Heap::RevokeAllThreadLocalAllocationStacks(Thread* self) {
// This must be called only during the pause.
CHECK(Locks::mutator_lock_->IsExclusiveHeld(self));
MutexLock mu(self, *Locks::runtime_shutdown_lock_);
MutexLock mu2(self, *Locks::thread_list_lock_);
std::list<Thread*> thread_list = Runtime::Current()->GetThreadList()->GetList();
for (Thread* t : thread_list) {
t->RevokeThreadLocalAllocationStack();
}
}这个函数定义在文件art/runtime/gc/heap.cc中。
Heap类的成员函数RevokeAllThreadLocalAllocationStacks首先是获得当前的ART运行时线程列表,然后再通过Thread类的成员函数RevokeThreadLocalAllocationStack回收每一个ART运行时线程的局部Allocation Stack。
Thread类的成员函数RevokeThreadLocalAllocationStack的实现如下所示:
inline void Thread::RevokeThreadLocalAllocationStack() {
......
tlsPtr_.thread_local_alloc_stack_end = nullptr;
tlsPtr_.thread_local_alloc_stack_top = nullptr;
}这个函数定义在文件art/runtime/thread-inl.h中。
从这里就可以看到,回收一个ART运行时线程的局部Allocation Stack,只需要将它的栈顶指针和最大栈顶指针值设置为nullptr即可。
了解了ART运行时线程的局部分配缓冲和局部Allocation Stack的回收过程之后,接下来我们继续分析SemiSpace类的成员函数BindBitmaps的实现,它是用来确定哪些Space需要进行GC,哪些Space不需要进行GC的,如下所示:
void SemiSpace::BindBitmaps() {
TimingLogger::ScopedTiming t(__FUNCTION__, GetTimings());
WriterMutexLock mu(self_, *Locks::heap_bitmap_lock_);
// Mark all of the spaces we never collect as immune.
for (const auto& space : GetHeap()->GetContinuousSpaces()) {
if (space->GetGcRetentionPolicy() == space::kGcRetentionPolicyNeverCollect ||
space->GetGcRetentionPolicy() == space::kGcRetentionPolicyFullCollect) {
CHECK(immune_region_.AddContinuousSpace(space)) << "Failed to add space " << *space;
} else if (space->GetLiveBitmap() != nullptr) {
if (space == to_space_ || collect_from_space_only_) {
if (collect_from_space_only_) {
// Bind the bitmaps of the main free list space and the non-moving space we are doing a
// bump pointer space only collection.
CHECK(space == GetHeap()->GetPrimaryFreeListSpace() ||
space == GetHeap()->GetNonMovingSpace());
}
CHECK(space->IsContinuousMemMapAllocSpace());
space->AsContinuousMemMapAllocSpace()->BindLiveToMarkBitmap();
}
}
}
if (collect_from_space_only_) {
// We won't collect the large object space if a bump pointer space only collection.
is_large_object_space_immune_ = true;
}
}这个函数定义在文件art/runtime/gc/collector/semi_space.cc中。
Semi-Space GC和Generational Semi-Space GC只涉及到Image Space、Zygote Space、Non Moving Space和Bump Pointer Space四种Continuous Space,它们的回收策略分别为kGcRetentionPolicyNeverCollect、kGcRetentionPolicyFullCollect、kGcRetentionPolicyAlwaysCollect和kGcRetentionPolicyAlwaysCollect。由此可见,在Semi-Space GC和Generational Semi-Space GC中,Image Space和Zygote Space都是不需要进行GC处理的,方法是将它们增加到SemiSpace类的成员变量immune_region_描述的一个无需要进行垃圾回收的区域去。
从前面ART运行时Compacting GC堆创建过程分析一文可以知道,Non Moving Space是一种Ros Alloc Space或者Dl Malloc Space,它是具有Live Bitmap的。然而,Bump Pointer Space是不具有Live Bitmap的,因此,在Semi-Space GC和Generational Semi-Space GC中,如果指定了仅仅只处理From Space,即SemiSpace类的成员变量collect_from_space_only_等于true,那么Non Moving Space也是不需要进行GC处理的,方法是将它的Mark Bitmap指向Live Bitmap,
此外,理论上说,Semi-Space GC和Generational Semi-Space GC的To Space只可能是一个Bump Pointer Space,由于Bump Pointer Space不具有Live Bitmap的,因此SemiSpace类的成员函数BindBitmaps是不需要对它进行特殊处理的。但是从前面ART运行时Compacting GC为新创建对象分配内存的过程分析一文可以知道,在对Main Space执行同构空间压缩时,也是通过执行一次Semi-Space GC和Generational Semi-Space GC来执行的。在这种情况下,To Space是一个Main Backup Space,它是具有Live Bitmap的。但是,在Semi-Space GC和Generational Semi-Space GC中,是不允许对To Space进行GC处理的。因此,当SemiSpace类的成员函数BindBitmaps当现一个Space既具有Live Bitmap,又是作为To Space时,也需要将它的Mark Bitmap指向Live Bitmap。
最后,Semi-Space GC和Generational Semi-Space GC还涉及一个Large Object Space。如果指定了仅仅只处理From Space,即SemiSpace类的成员变量collect_from_space_only_等于true,那么也是不需要对Large Object Space进行GC处理的。这里通过将SemiSpace类的成员变量is_large_object_space_immune_设置为true表明不要对Large Object Space进行GC处理。
现在,准备工作已经完成,接下来我们就继续分析SemiSpace类的成员函数MarkRoots和MarkReachableObjects,以及了解Semi-Space GC和Generational Semi-Space GC的核心执行过程,也就是将From Space拷贝到To Space或者Promote Space的过程。
SemiSpace类的成员函数MarkRoots的实现如下所示:
void SemiSpace::MarkRoots() {
TimingLogger::ScopedTiming t(__FUNCTION__, GetTimings());
Runtime::Current()->VisitRoots(MarkRootCallback, this);
}这个函数定义在文件art/runtime/gc/collector/semi_space.cc。
SemiSpace类的成员函数MarkRoots通过调用Runtime类的成员函数VisitRoots来遍历根集对象,具体可以参考前面ART运行时垃圾收集(GC)过程分析一文,对于每一个根集对象,都会调用SemiSpace类的静态成员函数MarkRootCallback进行处理。
SemiSpace类的静态成员函数MarkRootCallback的实现如下所示:
void SemiSpace::MarkRootCallback(Object** root, void* arg, uint32_t /*thread_id*/,
RootType /*root_type*/) {
auto ref = StackReference<mirror::Object>::FromMirrorPtr(*root);
reinterpret_cast<SemiSpace*>(arg)->MarkObject(&ref);
if (*root != ref.AsMirrorPtr()) {
*root = ref.AsMirrorPtr();
}
}这个函数定义在文件art/runtime/gc/collector/semi_space.cc。
在前面ART运行时Compacting GC简要介绍和学习计划一文中,我们已经分析过SemiSpace类的静态成员函数MarkRootCallback的实现了,因此这里不再详述。
SemiSpace类的静态成员函数MarkRootCallback调用了另外一个成员函数MarkObject来处理根集对象root,它的实现如下所示:
template<bool kPoisonReferences>
inline void SemiSpace::MarkObject(
mirror::ObjectReference<kPoisonReferences, mirror::Object>* obj_ptr) {
mirror::Object* obj = obj_ptr->AsMirrorPtr();
if (obj == nullptr) {
return;
}
if (kUseBakerOrBrooksReadBarrier) {
// Verify all the objects have the correct forward pointer installed.
obj->AssertReadBarrierPointer();
}
if (from_space_->HasAddress(obj)) {
mirror::Object* forward_address = GetForwardingAddressInFromSpace(obj);
// If the object has already been moved, return the new forward address.
if (UNLIKELY(forward_address == nullptr)) {
forward_address = MarkNonForwardedObject(obj);
DCHECK(forward_address != nullptr);
// Make sure to only update the forwarding address AFTER you copy the object so that the
// monitor word doesn't Get stomped over.
obj->SetLockWord(
LockWord::FromForwardingAddress(reinterpret_cast<size_t>(forward_address)), false);
// Push the object onto the mark stack for later processing.
MarkStackPush(forward_address);
}
obj_ptr->Assign(forward_address);
} else if (!collect_from_space_only_ && !immune_region_.ContainsObject(obj)) {
BitmapSetSlowPathVisitor visitor(this);
if (!mark_bitmap_->Set(obj, visitor)) {
// This object was not previously marked.
MarkStackPush(obj);
}
}
}这个函数定义在文件art/runtime/gc/collector/semi_space-inl.h中。
在前面ART运行时Compacting GC简要介绍和学习计划一文中,我们已经分析过SemiSpace类的成员函数MarkObject的实现了,因此这里不再详述。我们重点是分析这里调用到的SemiSpace类的另外一个成员函数MarkNonForwardedObject的实现,它涉及到对象的移动过程,如下所示:
mirror::Object* SemiSpace::MarkNonForwardedObject(mirror::Object* obj) {
const size_t object_size = obj->SizeOf();
size_t bytes_allocated;
mirror::Object* forward_address = nullptr;
if (generational_ && reinterpret_cast<byte*>(obj) < last_gc_to_space_end_) {
// If it's allocated before the last GC (older), move
// (pseudo-promote) it to the main free list space (as sort
// of an old generation.)
forward_address = promo_dest_space_->AllocThreadUnsafe(self_, object_size, &bytes_allocated,
nullptr);
if (UNLIKELY(forward_address == nullptr)) {
// If out of space, fall back to the to-space.
forward_address = to_space_->AllocThreadUnsafe(self_, object_size, &bytes_allocated, nullptr);
......
} else {
bytes_promoted_ += bytes_allocated;
......
// Handle the bitmaps marking.
accounting::ContinuousSpaceBitmap* live_bitmap = promo_dest_space_->GetLiveBitmap();
......
accounting::ContinuousSpaceBitmap* mark_bitmap = promo_dest_space_->GetMarkBitmap();
.....
if (collect_from_space_only_) {
......
// If a bump pointer space only collection, delay the live
// bitmap marking of the promoted object until it's popped off
// the mark stack (ProcessMarkStack()). The rationale: we may
// be in the middle of scanning the objects in the promo
// destination space for
// non-moving-space-to-bump-pointer-space references by
// iterating over the marked bits of the live bitmap
// (MarkReachableObjects()). If we don't delay it (and instead
// mark the promoted object here), the above promo destination
// space scan could encounter the just-promoted object and
// forward the references in the promoted object's fields even
// through it is pushed onto the mark stack. If this happens,
// the promoted object would be in an inconsistent state, that
// is, it's on the mark stack (gray) but its fields are
// already forwarded (black), which would cause a
// DCHECK(!to_space_->HasAddress(obj)) failure below.
} else {
// Mark forward_address on the live bit map.
live_bitmap->Set(forward_address);
// Mark forward_address on the mark bit map.
......
mark_bitmap->Set(forward_address);
}
}
} else {
// If it's allocated after the last GC (younger), copy it to the to-space.
forward_address = to_space_->AllocThreadUnsafe(self_, object_size, &bytes_allocated, nullptr);
if (forward_address != nullptr && to_space_live_bitmap_ != nullptr) {
to_space_live_bitmap_->Set(forward_address);
}
}
// If it's still null, attempt to use the fallback space.
if (UNLIKELY(forward_address == nullptr)) {
forward_address = fallback_space_->AllocThreadUnsafe(self_, object_size, &bytes_allocated,
nullptr);
......
accounting::ContinuousSpaceBitmap* bitmap = fallback_space_->GetLiveBitmap();
if (bitmap != nullptr) {
bitmap->Set(forward_address);
}
}
++objects_moved_;
bytes_moved_ += bytes_allocated;
// Copy over the object and add it to the mark stack since we still need to update its
// references.
saved_bytes_ +=
CopyAvoidingDirtyingPages(reinterpret_cast<void*>(forward_address), obj, object_size);
......
return forward_address;
}这个函数定义在文件art/runtime/gc/collector/semi_space.cc中。
参数obj就是即将要被移动的对象。它要被移动到哪里去呢?有三个可能的地方,分别是Promote Space、To Space和Fallback Space。前面提到,对于Generational Semi-Space GC来说,Promote Space和Fallback Space实际上都是ART运行堆的Main Space。但是对于Semi-Space GC来说,没有Promote Space,并且Fallback Space是ART运行时堆的Non Moving Space。
要将对象obj移动至Promote Space,需要满足两个条件。第一个条件是当前执行的是Generational Semi-Space GC,即SemiSpace类的成员变量generational_的值等于true。第二个条件是对象obj是一个老生代对象,也就是它必须要是上一次Generational Semi-Space GC执行过后才分配的。前面我们提到,SemiSpace类的成员变量last_gc_to_space_end_记录的是上一次Generational Semi-Space GC执行过后,已分配对象在From Space(上一次Generational Semi-Space GC的To Space)占据的最大内存地址值。因此,只要对象obj的地址值大于SemiSpace类的成员变量last_gc_to_space_end_的值,我们就可以认为它是一个老生代对象。
为了能够将对象obj移动至Promote Space,我们首先需要在Promote Space中分配一块与对象obj相同大小的内存,这是通过调用SemiSpace类的成员变量promo_dest_space_指向的一个ContinuousMemMapAllocSpace对象的成员函数AllocThreadUnsafe来实现的。但是有可能Promote Space已经满了,不能满足请求分配的内存。在这种情况下,就需要退回来在To Space进行申请。这意味着要将对象obj移动到To Space中去。
由于对象obj已经确定是一个在当前GC中存活的对象,因此当我们将它移动至另外一个Space时,需要将该Space的Live Bitmap的对应位设置为1。但是有一种特殊情况,就是当前执行的Generational Semi-Space GC决定仅仅对From Space进行GC处理。在这种情况下,后面在调用Heap类的成员函数MarkReachableObjects处理可达对象时,需要处理Promote Space对From Space的引用情况。这通常是通过Dirty Card来处理的。记住,当GC不是处理所有的Space的时候,所有存活的对象包括:
1. 位于需要处理的Space上的根集对象;
2. Dirty Card记录的位于不需要处理的Space的对象对需要处理的Space上的对象的引用;
3. 上述两种对象可达的位于需要处理的Space上的对象。
另外,在不使用Dirty Card的情况下,也有可能采用一种方法来确定上述第2种对象可达的对象,即通过遍历位于不需要处理的Space的Live Bitmap来确有哪此对象引用了需要处理的Space的对象。
如果当前执行的Generational Semi-Space GC决定仅仅对From Space进行GC处理,那么就符合GC不是处理所有的Space的条件。在这种情况下,需要处理的Space就是From Space,而Promote Space就是不需要处理的Space。现在我们从Promote Space分配了一个新的对象,作为对象obj移动后的新对象,如果我们将它在Promote Space的Live Bitmap对应的位设置为1,那么就会导致在不使用Dirty Card的情况下,后面在调用Heap类的成员函数MarkReachableObjects处理可达对象时,会对该被移动对象obj进行处理。这样做是不合理的,因为当前函数执行完毕,移动后的对象obj已经被压入到Mark Stack中。压入到Mark Stack的对象称为Gray对象,意味着它们的引用还没有被处理。但是在调用Heap类的成员函数MarkReachableObjects处理可达对象时,执行的操作就是处理对象的引用情况。这些引用已经被处理过的对象称为Black对象。一个对象不可能同时作为Gray对象和Black对象存在,因此,针对这种情况,就会延迟设置被移动对象obj在Promote Space的Live Bitmap的对应位。那么延迟到什么时候呢?很自然地,就是延迟到Heap类的成员函数MarkReachableObjects处理完成位于不需要处理的Space的对象对位于需要处理的Space的对象的引用之后,最合适的地方就是SemiSpace类的成员函数ProcessMarkStack。后面我们将会看到相关的代码实现。
另一方面,如果当前执行的Generational Semi-Space GC决定不仅仅是对From Space进行GC处理,也就是说也会对Promote Space也进行GC处理,这样后面调用Heap类的成员函数MarkReachableObjects处理可达对象时,就不会涉及到Promote Space。因此,这时候就要将被移动对象在Promote Space的Live Bitmap上对应的位设置为1。同时,也会将对应的Mark Bitmap位设置为1,以表示该对象在当前Generational Semi-Space GC执行过后,仍然是存活的。
在不满足将对象obj移动至Promote Space的条件下,接下来需要考虑的就是将对象obj移动至To Space中。于是,在这种情况下,就在To Space中分配一块与对象obj相同大小的内存块。由于To Space在接下来调用Heap类的成员函数MarkReachableObjects处理可达对象时不是需要处理的,因此这里就可以将被移动对象obj在To Space的Live Bitmap的对应位设置为1。注意,前面提到,To Space有可能是一个Bump Pointer Space,也有可能是一个Main Backup Space。由于Bump Pointer Space是没有Live Bitmap的,因此在设置被移动对象obj在To Space的Live Bitmap的对应位时,需要先判断Live Bitmap存不存在。
最后,如果不能成功地从To Space分配到一块用于移动对象obj的内存,那么就只好将对象obj移动到Fallback Space中去了。于是,在这种情况下,就在Fallback Space中分配一块与对象obj相同大小的内存块,并且在Fallback Space存在Live Bitmap的情况下,将移动对象obj在Fallback Space的Live Bitmap的对应位设置为1。
从目标Space中分配到与对象obj相同大小的内存块之后,接下来要做的就是将对象obj拷贝到该块内存去了,这是通过调用SemiSpace类的成员函数CopyAvoidingDirtyingPages来实现的,如下所示:
static inline size_t CopyAvoidingDirtyingPages(void* dest, const void* src, size_t size) {
if (LIKELY(size <= static_cast<size_t>(kPageSize))) {
// We will dirty the current page and somewhere in the middle of the next page. This means
// that the next object copied will also dirty that page.
// TODO: Worth considering the last object copied? We may end up dirtying one page which is
// not necessary per GC.
memcpy(dest, src, size);
return 0;
}
size_t saved_bytes = 0;
byte* byte_dest = reinterpret_cast<byte*>(dest);
......
// Process the start of the page. The page must already be dirty, don't bother with checking.
const byte* byte_src = reinterpret_cast<const byte*>(src);
const byte* limit = byte_src + size;
size_t page_remain = AlignUp(byte_dest, kPageSize) - byte_dest;
// Copy the bytes until the start of the next page.
memcpy(dest, src, page_remain);
byte_src += page_remain;
byte_dest += page_remain;
DCHECK_ALIGNED(reinterpret_cast<uintptr_t>(byte_dest), kPageSize);
DCHECK_ALIGNED(reinterpret_cast<uintptr_t>(byte_dest), sizeof(uintptr_t));
DCHECK_ALIGNED(reinterpret_cast<uintptr_t>(byte_src), sizeof(uintptr_t));
while (byte_src + kPageSize < limit) {
bool all_zero = true;
uintptr_t* word_dest = reinterpret_cast<uintptr_t*>(byte_dest);
const uintptr_t* word_src = reinterpret_cast<const uintptr_t*>(byte_src);
for (size_t i = 0; i < kPageSize / sizeof(*word_src); ++i) {
// Assumes the destination of the copy is all zeros.
if (word_src[i] != 0) {
all_zero = false;
word_dest[i] = word_src[i];
}
}
if (all_zero) {
// Avoided copying into the page since it was all zeros.
saved_bytes += kPageSize;
}
byte_src += kPageSize;
byte_dest += kPageSize;
}
// Handle the part of the page at the end.
memcpy(byte_dest, byte_src, limit - byte_src);
return saved_bytes;
}这个函数定义在文件art/runtime/gc/collector/semi_space.cc中。
SemiSpace类的成员函数CopyAvoidingDirtyingPages不是简单地调用内存拷贝函数memcpy一块内存从source拷贝到destination中,因为这样会导致destination对应的内存页在内核中被标记为dirty,这样的话就会增加内核对它的各种内存管理。这里我们是将对象从From Space拷贝到To Space。这里的To Space即为上次GC时的From Space。前面分析SemiSpace类的成员函数MarkingPhase提到,上次GC执行到最后,会将From Space的内容清零。因此,这里在拷贝内存的过程中,就可以做一个优化,对于source中内存等于0的块,可以不对destination对应的内存块执行拷贝操作,这样就可以避免它在内核中被标记为dirty。
在具体执行过程中,是按内存页进行的。也就是说,对于要拷贝的内容中前后不是按内存页对齐的内存块,直接调用内存拷贝函数memcpy进行拷贝。而对于中间按内存页对齐的部分内存,就按照word来依次检查source中的值是否等于0。只有在不等于0的情况下,才会将其拷贝到destination中。
这样,根集对象的处理过程就执行完成了,接下来需要继续调用Heap类的成员函数MarkReachableObjects处理可达对象,它的实现如下所示:
void SemiSpace::MarkReachableObjects() {
TimingLogger::ScopedTiming t(__FUNCTION__, GetTimings());
{
TimingLogger::ScopedTiming t2("MarkStackAsLive", GetTimings());
accounting::ObjectStack* live_stack = heap_->GetLiveStack();
heap_->MarkAllocStackAsLive(live_stack);
live_stack->Reset();
}
for (auto& space : heap_->GetContinuousSpaces()) {
// If the space is immune then we need to mark the references to other spaces.
accounting::ModUnionTable* table = heap_->FindModUnionTableFromSpace(space);
if (table != nullptr) {
// TODO: Improve naming.
TimingLogger::ScopedTiming t2(
space->IsZygoteSpace() ? "UpdateAndMarkZygoteModUnionTable" :
"UpdateAndMarkImageModUnionTable",
GetTimings());
table->UpdateAndMarkReferences(MarkHeapReferenceCallback, this);
......
} else if (collect_from_space_only_ && space->GetLiveBitmap() != nullptr) {
// If the space has no mod union table (the non-moving space and main spaces when the bump
// pointer space only collection is enabled,) then we need to scan its live bitmap or dirty
// cards as roots (including the objects on the live stack which have just marked in the live
// bitmap above in MarkAllocStackAsLive().)
......
accounting::RememberedSet* rem_set = GetHeap()->FindRememberedSetFromSpace(space);
......
if (rem_set != nullptr) {
TimingLogger::ScopedTiming t2("UpdateAndMarkRememberedSet", GetTimings());
rem_set->UpdateAndMarkReferences(MarkHeapReferenceCallback, DelayReferenceReferentCallback,
from_space_, this);
......
} else {
TimingLogger::ScopedTiming t2("VisitLiveBits", GetTimings());
accounting::ContinuousSpaceBitmap* live_bitmap = space->GetLiveBitmap();
SemiSpaceScanObjectVisitor visitor(this);
live_bitmap->VisitMarkedRange(reinterpret_cast<uintptr_t>(space->Begin()),
reinterpret_cast<uintptr_t>(space->End()),
visitor);
}
}
}
CHECK_EQ(is_large_object_space_immune_, collect_from_space_only_);
if (is_large_object_space_immune_) {
TimingLogger::ScopedTiming t("VisitLargeObjects", GetTimings());
......
// Delay copying the live set to the marked set until here from
// BindBitmaps() as the large objects on the allocation stack may
// be newly added to the live set above in MarkAllocStackAsLive().
GetHeap()->GetLargeObjectsSpace()->CopyLiveToMarked();
// When the large object space is immune, we need to scan the
// large object space as roots as they contain references to their
// classes (primitive array classes) that could move though they
// don't contain any other references.
space::LargeObjectSpace* large_object_space = GetHeap()->GetLargeObjectsSpace();
accounting::LargeObjectBitmap* large_live_bitmap = large_object_space->GetLiveBitmap();
SemiSpaceScanObjectVisitor visitor(this);
large_live_bitmap->VisitMarkedRange(reinterpret_cast<uintptr_t>(large_object_space->Begin()),
reinterpret_cast<uintptr_t>(large_object_space->End()),
visitor);
}
// Recursively process the mark stack.
ProcessMarkStack();
}这个函数定义在文件art/runtime/gc/collector/semi_space.cc中。
前面提到,Heap类的成员函数MarkReachableObjects除了需要处理根集对象可达的对象之外,还需要处理Dirty Card可达对象。如果没有使用Dirty Card,那么就需要通过Live Bitmap来处理。从前面ART运行时Compacting GC为新创建对象分配内存的过程分析一文可以知道,当我们从ART运行时堆分配一个新的对象时,并不会马上就将其对应的Live Bitmap对应的位设置为1,而只是将其压入到Allocation Stack中。这是因为Live Bitmap只有在执行GC的过程中才会真正使用到,因此就可以延迟执行这一操作。现在就是位于执行GC的过程中,并且要使用到Live Bitmap中,因此就需要把保存在Allocation Stack中的对象在其对应的Space的Live Bitmap的对应位设置为1。这是通过调用Heap类的成员函数MarkAllocStackAsLive实现的。注意,在前面分析的Heap类的成员函数MarkingPhase中,已经将ART运行时的Allocation Stack与Live Stack进行交换过了,因此这里是针对Live Stack进行处理。
Heap类的成员函数MarkAllocStackAsLive的实现如下所示:
void Heap::MarkAllocStackAsLive(accounting::ObjectStack* stack) {
space::ContinuousSpace* space1 = main_space_ != nullptr ? main_space_ : non_moving_space_;
space::ContinuousSpace* space2 = non_moving_space_;
......
MarkAllocStack(space1->GetLiveBitmap(), space2->GetLiveBitmap(),
large_object_space_->GetLiveBitmap(), stack);
}这个函数定义在文件art/runtime/gc/heap.cc中。
在ART运行时堆中,从前面ART运行时Compacting GC为新创建对象分配内存的过程分析一文可以知道,保存在Allocation Stack中的对象有可能是从Main Space、Non Moving Space或者Large Object Space中分配的。也就是说,Heap类的成员函数MarkAllocStackAsLive需要获得这三个Space的Live Bitmap,以便可以设置保存在Allocation Stack的对象的Live Bitmap对应位。
由于Main Space是不一定存在的,例如,当前GC为Compacting GC时,就没有Main Space,这时候使用Non Moving Space的Live Bitmap来代替Main Space的Live Bitmap。有了上述三个Live Bitmap之后,接下来就调用Heap类的成员函数MarkAllocStack来标记保存在Allocation Stack的对象的Live Bitmap位。
Heap类的成员函数MarkAllocStack的实现如下所示:
void Heap::MarkAllocStack(accounting::ContinuousSpaceBitmap* bitmap1,
accounting::ContinuousSpaceBitmap* bitmap2,
accounting::LargeObjectBitmap* large_objects,
accounting::ObjectStack* stack) {
DCHECK(bitmap1 != nullptr);
DCHECK(bitmap2 != nullptr);
mirror::Object** limit = stack->End();
for (mirror::Object** it = stack->Begin(); it != limit; ++it) {
const mirror::Object* obj = *it;
if (!kUseThreadLocalAllocationStack || obj != nullptr) {
if (bitmap1->HasAddress(obj)) {
bitmap1->Set(obj);
} else if (bitmap2->HasAddress(obj)) {
bitmap2->Set(obj);
} else {
large_objects->Set(obj);
}
}
}
}这个函数定义在文件art/runtime/gc/heap.cc中。
Heap类的成员函数MarkAllocStack的实现很简单,它依次遍历保存在Allocation Stack的每一个对象,并且判断这些对象是位于哪个Live Bitmap中,就将哪个Live Bitmap的对应位设置为1。
这样,ART运行时的Allocation Stack就处理完毕,回到SemiSpace类的成员函数MarkReachableObjects中,接下来开始处理那些不需要进行GC处理的Space对那些需要进行GC处理的Space的引用。要么通过Dirty Card,要么通过Live Bitmap来获得上述的引用关系。通过Dirty Card处理的效率会更高,因为这种方式只有从上一次GC以来发生过修改的对象的才会进行处理。而通过Live Bitmap处理则不管是不是上一次GC以来发生过修改,只是存活的对象,都要进行处理。
从大的分类来看,不需要进行GC处理的Space分为Continuous Space和Discontinuous Space两大类,其中,Discontinuous Space就只有Large Object Space一种。接下来我们就分别分析这两类Space的处理过程。
首先看Continuous Space的处理。并不是所有的Continuous Space都是需要处理的。从前面分析的SemiSpace类的成员函数BindBitmap可以知道,Image Space和Zygote Space是必须要进行处理的。在SemiSpace类的成员变量collect_from_space_only_等于true的情况下,Non Moving Space也是需要在这里进行处理的。
ART运行时堆的所有Continuous Space可以通过调用Heap类的成员函数GetContinuousSpaces。获得的Continuous Space同时也包含了Bump Pointer Space。Bump Pointer Space只有From Space和To Space,它们都是不需要在这里进行处理的。因此,我们需要从获得的Continuous Space中过滤掉Bump Pointer Space。幸好,Bump Pointer Space是没有Live Bitmap的,因此,我们可以通过这一简单的事实将它们从获得的Continuous Space中过滤掉。
此外,对于Image Space和Zygote Space来说,它们通过Mod Union Table来记录它们对其它Space的引用修改情况。对于Non Moving Space来说,它通过Remember Set来记录它对From Space的引用修改情况。无论Mod Union Table还是Remember Set,它们都是通过Dirty Card来记录一个Space对另外一个Space的引用修改情况的。但是Non Moving Space也有可能不通过Remember Set来记录它对From Space的引用修改情况的。这取决于常量collector::SemiSpace::kUseRememberedSet的值。
有了前面这些知识之后,我们就很容易理解Heap类的成员函数MarkReachableObjects对Image Space、Zygote Space和Non Moving Space的处理了:
1. 对于Image Space和Zygote Space,调用与它们关联的ModUnionTable对象的成员函数UpdateAndMarkReferences处理那些从上次GC以来发生过引用类型的成员变量修改的对象。对于每一个这样的对象,都调用SemiSpace类的静态成员函数MarkHeapReferenceCallback对它们进行处理。
2. 对于Non Moving Space,只有在SemiSpace类的成员变量collect_from_space_only_等于true的情况下,才需要在这里进行处理。这一点我们在前面的分析中有提及到。如果Non Moving Space关联有RememberSet对象,那么就调用它的成员函数UpdateAndMarkReferences处理那些从上次GC以来发生引用类型的成员变量修改,并且这些修改后的成员变量引用了位于From Space的对象的对象。对于每一个这样的对象,都调用SemiSpace类的静态成员函数MarkHeapReferenceCallback或者DelayReferenceReferentCallback对它们进行处理。其中,前者用来处理非引用对象,而后者用来处理引用对象。如果Non Moving Space没有关联RememberSet对象,那么就通过它的Live Bitmap来处理它的存活对象对From Space的对象的引用情况,并且是通过SemiSpaceScanObjectVisitor类来处理Non Moving Space的每一个存活对象的。
接着再看对Discontinuous Space的处理,也就是对Large Object Space的处理。前面分析SemiSpace类的成员函数BindBitmaps时提到,当SemiSpace类的成员变量is_large_object_space_immune_等于true的时候,就表示不要对Large Object Space的垃圾对象进行回收。换句话说,在这里就需要对Large Object Space进行处理,即处理它对From Space的引用情况。这是通过遍历Large Object Space的Live Bitmap进行处理的,对于Large Object Space中的每一个存活对象,都通过SemiSpaceScanObjectVisitor类来处理它对From Space的引用情况。
在处理Large Object Space的时候,还有一点需要注意的是,前面在调用SemiSpace类的成员函数BindBitmaps中,我们只是通过SemiSpace类的成员变量is_large_object_space_immune_记录了Large Object Space不需要进行垃圾回收,但是没有像其它的不需要进行垃圾回收的Space一样,例如Non Moving Space,将它当前的Live Bitmap拷贝到Mark Bitmap中去。这样做有两个原因:
1. 其它的Space,也就是Non Moving Space,将它的Live Bitmap拷贝到Mark Bitmap,实际上只是让Mark Bitmap和Live Bitmap指向同一个Bitmap,这个操作没有执行真正内存拷贝操作。
2. 将Large Object Space的Live Bitmap拷贝到Mark Bitmap,是要执行真正的内存拷贝操作的,因为Large Object Space和Non Moving Space的Live/Mark Bitmap实现是不一样的。又由于在执行SemiSpace类的成员函数BindBitmaps的时候,Large Object Space的Live Bitmap还没有包含那些保存在Allocation Stack上的对象。因此,这里为了减少内存拷贝的次数,就等到将保存在Allocation Stack上的并且是在Large Object Space上分配的对象在Live Bitmap中的位都设置好之后,再调用LargeObjectSpace类的成员函数CopyLiveToMarked一次性完整地把Live Bitmap拷贝到Mark Bitmap中。
接下来,我们只分析SemiSpace类的静态成员函数MarkHeapReferenceCallback的实现,以便可以了解那些位于不需要进行垃圾回收的Space对需要进行垃圾回收的Space的引用情况是如何处理的,它的实现如下所示:
void SemiSpace::MarkHeapReferenceCallback(mirror::HeapReference<mirror::Object>* obj_ptr,
void* arg) {
reinterpret_cast<SemiSpace*>(arg)->MarkObject(obj_ptr);
}这个函数定义在文件art/runtime/gc/collector/semi_space.cc中。
从这里就可以看到,这里与前面处理根集对象的方式是一样的,都是通过调用SemiSpace类的成员函数MarkObject来对对象进行标记或者移动的操作的。关于SemiSpace类的静态成员函数MarkHeapReferenceCallback的被调用过程,还可以参考前面ART运行时Compacting GC简要介绍和学习计划一文。
回到Heap类的成员函数MarkReachableObjects中,这时候根集对象,以及Dirty Card引用的对象,均已经被标记和移动,现在就可以调用SemiSpace类的成员函数ProcessMarkStack对它们的可达对象进行递归标记和移动了。
SemiSpace类的成员函数ProcessMarkStack的实现如下所示:
void SemiSpace::ProcessMarkStack() {
TimingLogger::ScopedTiming t(__FUNCTION__, GetTimings());
accounting::ContinuousSpaceBitmap* live_bitmap = nullptr;
if (collect_from_space_only_) {
// If a bump pointer space only collection (and the promotion is
// enabled,) we delay the live-bitmap marking of promoted objects
// from MarkObject() until this function.
live_bitmap = promo_dest_space_->GetLiveBitmap();
DCHECK(live_bitmap != nullptr);
accounting::ContinuousSpaceBitmap* mark_bitmap = promo_dest_space_->GetMarkBitmap();
DCHECK(mark_bitmap != nullptr);
DCHECK_EQ(live_bitmap, mark_bitmap);
}
while (!mark_stack_->IsEmpty()) {
Object* obj = mark_stack_->PopBack();
if (collect_from_space_only_ && promo_dest_space_->HasAddress(obj)) {
// obj has just been promoted. Mark the live bitmap for it,
// which is delayed from MarkObject().
DCHECK(!live_bitmap->Test(obj));
live_bitmap->Set(obj);
}
ScanObject(obj);
}
}这个函数定义在文件art/runtime/gc/collector/semi_space.cc中。
之前处理过的根集对象和被Dirty Card引用的对象都被压入到了SemiSpace类的成员变量mark_stack_描述的一个Mark Stack中,现在通过调用SemiSpace类的成员函数ScanObject即可以对它们的可达对象进行递归遍历处理。
这里我们就还可以看到前面分析SemiSpace类的成员函数MarkNonForwardedObject提到的在仅仅回收From Space的垃圾的情况下,对移动到Promote Space的对象的Live Bitmap位的延迟处理。也就是说,在处理Mark Stack的过程中,如果一个对象位于Promote Space中,那么就将该对象在Promote Space的Live Bitmap位设置为1。只有经过这样的处理之后,后面的垃圾回收阶段才能正确处理那些从From Space拷贝到Promote Space的对象。
SemiSpace类的成员函数ScanObject的实现如下所示:
void SemiSpace::ScanObject(Object* obj) {
......
SemiSpaceMarkObjectVisitor visitor(this);
obj->VisitReferences<kMovingClasses>(visitor, visitor);
}这个函数定义在文件art/runtime/gc/collector/semi_space.cc中。
SemiSpace类的成员函数ScanObject通过SemiSpaceMarkObjectVisitor类的操作符号重载函数()处理对象obj每一个引用类型的成员变量,如下所示:
class SemiSpaceMarkObjectVisitor {
public:
explicit SemiSpaceMarkObjectVisitor(SemiSpace* collector) : collector_(collector) {
}
void operator()(Object* obj, MemberOffset offset, bool /* is_static */) const ALWAYS_INLINE
EXCLUSIVE_LOCKS_REQUIRED(Locks::mutator_lock_, Locks::heap_bitmap_lock_) {
// Object was already verified when we scanned it.
collector_->MarkObject(obj->GetFieldObjectReferenceAddr<kVerifyNone>(offset));
}
void operator()(mirror::Class* klass, mirror::Reference* ref) const
SHARED_LOCKS_REQUIRED(Locks::mutator_lock_)
EXCLUSIVE_LOCKS_REQUIRED(Locks::heap_bitmap_lock_) {
collector_->DelayReferenceReferent(klass, ref);
}
private:
SemiSpace* const collector_;
};SemiSpaceMarkObjectVisitor类定义在文件art/runtime/gc/collector/semi_space.cc中。
取决于成员变量的引用类型,调用不同的版本的操作符号重载函数()。如果成员变量引用的是一个引用对象,即Soft Reference、Weak Reference、Phantom Reference和Finalizer Reference这类对象,那么就调用SemiSpace类的成员函数DelayReferenceReferent延迟到后面调用SemiSpace类的成员函数ProcessReferences时再处理。如果成员变量引用的是一个普通对象,那么就调用我们前面已经分析过的SemiSpace类的成员函数MarkObject对它进行标记和移动等处理。
至此,所有的存活对象就都已经标记和移动完毕,接下来就开始执行Semi-Space GC或者Generational Semi-Space GC的回收阶段了,这是通过调用SemiSpace类的成员函数ReclaimPhase来实现的,如下所示:
void SemiSpace::ReclaimPhase() {
TimingLogger::ScopedTiming t(__FUNCTION__, GetTimings());
WriterMutexLock mu(self_, *Locks::heap_bitmap_lock_);
// Reclaim unmarked objects.
Sweep(false);
// Swap the live and mark bitmaps for each space which we modified space. This is an
// optimization that enables us to not clear live bits inside of the sweep. Only swaps unbound
// bitmaps.
SwapBitmaps();
// Unbind the live and mark bitmaps.
GetHeap()->UnBindBitmaps();
.......
if (generational_) {
// Record the end (top) of the to space so we can distinguish
// between objects that were allocated since the last GC and the
// older objects.
last_gc_to_space_end_ = to_space_->End();
}
}这个函数定义在文件art/runtime/gc/collector/semi_space.cc中。
SemiSpace类的成员函数ReclaimPhase主要是执行以下四个操作:
1. 调用SemiSpace类的成员函数Sweep回收各个Space的垃圾对象,即那些Mark Bitmap位等于0,但是Live Bitmap位等于1的对象。
2. 调用从父类GarbageCollector继承下来的成员函数SwapBitmaps交换各个Space的Mark Bitmap和Live Bitmap,以便可以将上次GC以来存活下来的对象记录在Live Bitmap中。
3. 调用Heap类的成员函数UnBindBitmaps重置各个Space的Mark Bitmap,以便下次GC时可以使用。
4. 对于Generational Semi-Space GC,即在SemiSpace类的成员变量generational_的值等于true的情况下,将当前To Space当前已经分配出去的最大内存地址值记录在SemiSpace类的成员变量last_gc_to_space_end_中,以前下次再执行Generational Semi-Space GC时,可以通过该成员变量来区分新生代和老生代对象。
前面三个操作可以参考前面ART运行时垃圾收集(GC)过程分析一文。这里不再详细分析。
这样,Semi-Space GC或者Generational Semi-Space GC的回收阶段也执行完成了,最后需要执行的一个阶段是结束阶段。这是通过调用SemiSpace类的成员函数FinishPhase来实现的,如下所示:
void SemiSpace::FinishPhase() {
TimingLogger::ScopedTiming t(__FUNCTION__, GetTimings());
// Null the "to" and "from" spaces since compacting from one to the other isn't valid until
// further action is done by the heap.
to_space_ = nullptr;
from_space_ = nullptr;
CHECK(mark_stack_->IsEmpty());
mark_stack_->Reset();
if (generational_) {
// Decide whether to do a whole heap collection or a bump pointer
// only space collection at the next collection by updating
// collect_from_space_only_.
if (collect_from_space_only_) {
// Disable collect_from_space_only_ if the bytes promoted since the
// last whole heap collection or the large object bytes
// allocated exceeds a threshold.
bytes_promoted_since_last_whole_heap_collection_ += bytes_promoted_;
bool bytes_promoted_threshold_exceeded =
bytes_promoted_since_last_whole_heap_collection_ >= kBytesPromotedThreshold;
uint64_t current_los_bytes_allocated = GetHeap()->GetLargeObjectsSpace()->GetBytesAllocated();
uint64_t last_los_bytes_allocated =
large_object_bytes_allocated_at_last_whole_heap_collection_;
bool large_object_bytes_threshold_exceeded =
current_los_bytes_allocated >=
last_los_bytes_allocated + kLargeObjectBytesAllocatedThreshold;
if (bytes_promoted_threshold_exceeded || large_object_bytes_threshold_exceeded) {
collect_from_space_only_ = false;
}
} else {
// Reset the counters.
bytes_promoted_since_last_whole_heap_collection_ = bytes_promoted_;
large_object_bytes_allocated_at_last_whole_heap_collection_ =
GetHeap()->GetLargeObjectsSpace()->GetBytesAllocated();
collect_from_space_only_ = true;
}
}
// Clear all of the spaces' mark bitmaps.
WriterMutexLock mu(Thread::Current(), *Locks::heap_bitmap_lock_);
heap_->ClearMarkedObjects();
}这个函数定义在文件art/runtime/gc/collector/semi_space.cc中。
SemiSpace类的成员函数FinishPhase主要执行以下四个操作:
1. 将SemiSpace类的成员变量from_space_和to_space_置空。这两个成员变量在下一次执行Semi-Space GC或者Generational Semi-Space GC时之前,会被重新设置。
2. 将SemiSpace类的成员变量mark_stack_描述的Mark Stack清零。
3. 确定下一次执行Generational Semi-Space GC时,是否只仅仅回收From Space的垃圾。如果当前执行的Generational Semi-Space GC是仅仅回收From Space的垃圾,那么在满足以下两个条件之一时,下一次执行Generational Semi-Space GC时,就不是仅仅回收From Space的垃圾了:1)上一次执行不仅仅回收From Space的垃圾的Generational Semi-Space GC以来,总共移动至Promote Space的对象超过阀值kBytesPromotedThreshold(4MB);2) 当前从Large Object Space上分配的内存字节数,比上次执行不仅仅回收From Space的垃圾的Generational Semi-Space GC时在Large Object Space上分配的内存字节数,超过阀值kLargeObjectBytesAllocatedThreshold(16MB)。这两个条件的意思是说,当Promote Space或者Large Object Space可用的空闲内存不多时,就不能仅仅是回收From Space的垃圾,也要对它们的垃圾进行回收,不然的话,下次再执行Generational Semi-Space GC的时候,Promote Space就不够用了,或者下次再分配Large Object时,Large Object Space不够用。
4. 调用Heap类的成员函数ClearMarkedObjects清零各个Space的Mark Bitmap。
这样,Semi-Space GC或者Generational Semi-Space GC的结束阶段也执行完成了,整个Semi-Space GC或者Generational Semi-Space GC的执行过程也分析完成了。从中我们就可以看到它们与Mark-Sweep GC的两个核心区别:
1. Semi-Space GC或者Generational Semi-Space GC的执行是Stop-the-world的,而Mark-Sweep GC可以Concurrent执行的。
- Semi-Space GC或者Generational Semi-Space GC在执行的过程中需要两个Space,并且需要移动对象,而Mark-Sweep GC仅需要一个Space就可以执行,并且不需要移动对象。
这样的区别就决定了Semi-Space GC或者Generational Semi-Space GC的执行效率没有Mark-Sweep GC高,但是由于它在移动对象的同时使得对象可以紧凑地排列在一起,从而可以解决内存碎片问题,这是Mark-Sweep GC没法做到的。因此,Semi-Space GC或者Generational Semi-Space GC适合作为Background GC来执行,因为当前应用程序运行在Background时,应用程序的响应时间是不重要的,但是我们却可以借这个时机来解决内存碎片问题。
在接下来一篇文章中,我们将继续分析ART运行时引进的第三种Compacting GC -- Mark-Compact GC。Mark-Compact GC同样可以解决内存碎片问题,同样也是通过移动对象来实现的,不过它只需要一个Space就可以执行,敬请关注!更多信息也可以关注老罗的新浪微博:http://weibo.com/shengyangluo。